
This document describes how to set up an OCR engine, prepare the images for recognition, and convert from pdf files to text. Here at the Military Yearbook Project we often have the need to convert old military yearbooks in.pdf format to text, then ultimately to html. Most of the old MOS codes used as references on this website were converted using this method. We use a combination of software to output the text.
This basic guide will cover useage on a linux system since this website was created and is maintained using Ubuntu 10.04.
Software used.
1. Tesseract OCR Engine: Tesseract is an OCR (Optical Character Recognition) engine that is considered to be one of the most accurate free OCR engines out there. Get Tesseract 1.03 or install from the Synaptic Package Manager
sudo apt-get update && sudo apt-get install tesseract-ocr tesseract-ocr-data
2. Imagemagick: Imagemagick will be needed since Tesseract only accepts .tif image files as input. The Gimp does'nt seem to convert images correctly to the uncompressed .tif format. Install Imagemagick with the Synaptic Package Manager.
sudo apt-get update && sudo apt-get install imagemagick
3. Gimp: We will use the Gimp to clean up the images before converting with Tesseract. Install the Gimp with the Synaptic Package Manager.
sudo apt-get update && sudo apt-get install gimp
Preparing the images.
Since we want to get the most accurate results possible from Tesseract, we will need to first clean up the images. Sometimes it is easier to obtain the best results in Tesseract by chopping up the original image into individual columns of image text and saving as smaller jpg files. Assuming you have a scan saved in .jpg format which has been extracted from the original .pdf file, the following steps will help to clean up the image.
Spot cleaning: Load the image into Gimp and use the erase tool to remove artifacts and other unwanted blemishes from the image. This step will greatly reduce the chance of random garbage that Tesseract will output.

Change the threshold: Use the threshold function in Gimp to get rid of tinting and lighting issues from the original scan.
Tools - Color Tools - Threshold
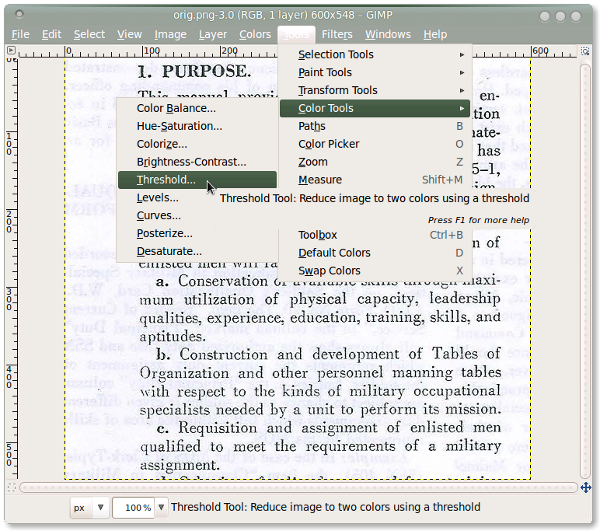
Before Screenshot: Before applying the threshold function in Gimp.

After Screenshot: Shading and tinting is removed.
Change the image Mode: Reduce the image to black and white. This step isn't absolutely necessary but in some cases improves the character recognition. Image - Mode - Indexed
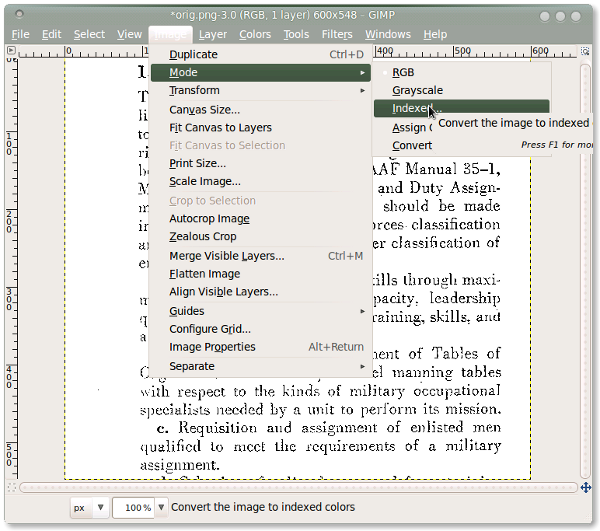
Converting the images.
We will use Mogrify (part of Imagemagick) to convert the images to .tif format before feeding into Tesseract.
mogrify -format tif -quality 100 *.jpg
After the images are converted to .tif format, we can run them through Tesseract:
tesseract sample.tif sample
Here's a small batch file to convert all .jpg images in a directory then convert to text.
#!/bin/sh echo "------------------ convert ------------------" mogrify -format tif -quality 100 *.jpg
echo "------- Tesseract ---------" for i in *.tif; do tesseract "$i" "`basename "$i" .tif`" -l eng; done



